阿里云HAIL全自研数据中心网络技术分析
发表时间: 2023-12-29 01:15:35 发布于:行业新闻
云计算数据中心是云计算的算力载体,今天所有的云计算服务都在数据中心这样一个“超级”中进行着快速运算,并利用互联网将服务快速触达全球用户和各行各业。云计算数据中心大致上可与一台电脑进行类比,包含和制冷系统。如果你想了解数据中心网络,拆开电脑机框,主板上那一条条连接着各种部件的金属走线所发挥的作用,就是数据中心这个“超级电脑”中网络在做的工作。当然,数据中心网络系统远比一台电脑的内部互联复杂得多。
数据中心诞生之前,网络大多数都用在全球互联,以及企业内部的组网互通,俗称公网和内网。初期的数据中心基于服务传统企业网的技术进行构建,逐渐发展成为一个独立的场景。互联网和云计算公司为了向公众提供互联网服务(如媒体信息通信交流、搜索查阅、网上购物等),需要自身具备服务全国甚至全球用户的计算、存储和网络互联能力,这要求后端技术平台可处理高并发的请求,内部系统则要对数据来进行快速的存储、计算、搜索,再经由互联网络将结果输出给用户。这种模型对互联网和云计算的集中化算力能力提出了更高的要求,数据中心的场景也随之诞生。
初期的数据中心网络采用企业级的网络设备做数据中心组网,如VPC、堆叠,大的二层域和OSPF路由协议等。这些网络技术在较小的组网规模条件下并不可能会出现太大的问题,但伴随着互联网数据中心的算力规模慢慢的变大,企业级的数据中心网络技术就面临着性能、稳定性、大规模运营等方面的挑战。
阿里巴巴从2013年进入标准化数据中心网络架构阶段,开始基于商用设备做数据中心网络的标准化构建,并从互联拓扑、互联协议层面进行改善,逐步采用标准通用的适合数据中心组网的技术选型。

同一时期,为了进一步自主掌控数据中心网络技术栈,为产品打造更高效稳定的网络基础设施,阿里云开始了全自研体系的设计和研发。HAILDC5.2是第一代采用全自研交换机和光互联的数据中心网络架构,通过单芯片自研盒式设备来构建多平面scale out(横向可扩展)的分布式数据中心网络。
单芯片的架构设计极大地简化了网络设备软硬件复杂度,让研发工作专注在阿里云HAIL数据中心网络架构中使用的功能,考虑整网系统的稳定性,而不必开发陷入复杂但效用不高的多芯片软硬件功能。
多年积累的网络运维沉淀和自动化平台能力,使得数据中心网络系统具备了实现分布式大规模交付运维的条件,大规模网络设备的交付运维监控自动化,从经验积累逐步转变成NET系统平台(阿里云网络交付运维自动化的监管控平台)的能力。
全自研的软硬件设备会与后端的监控管控自动化作为一个整体进行设计和研发,使得网络设备与监管控系统的联动更加顺畅,实现了高精度、高实时性的网络性能监控,快速察觉缺陷并自动化响应,数据中心自研系统成为一个整体,而不单单是自研的网络设备。
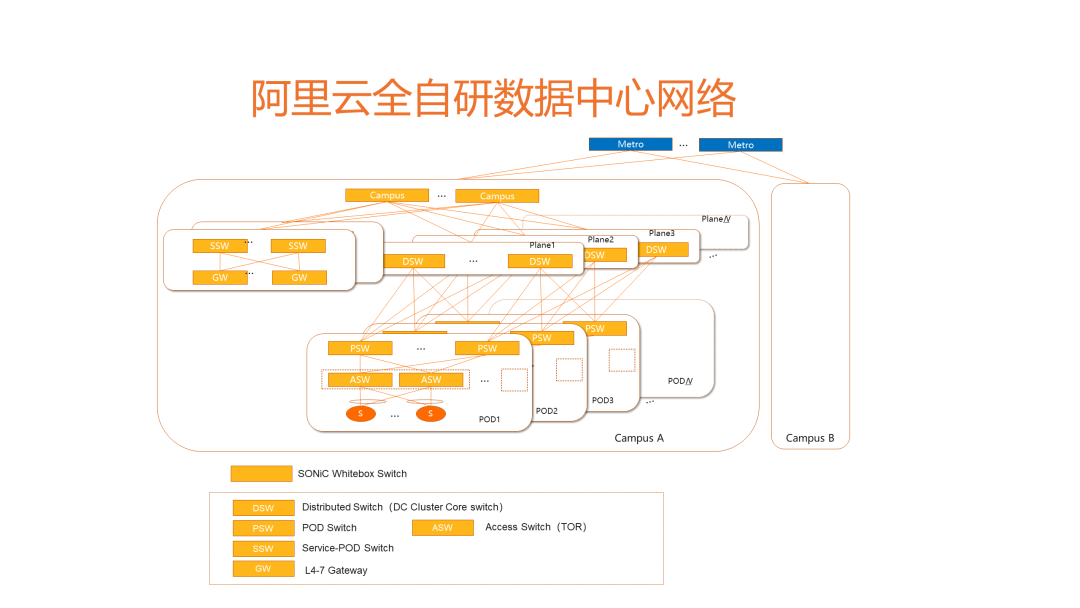
自2019年,阿里云新建数据中心就全面采用了基于AliNOS (阿里云自研网络操作系统)的自研交换机,如上图,包括园区核心、集群核心、POD核心、接入TOR,以及基于P4可编程的网关设备SNA。
多平面互联使得网络集群规模灵活弹性,三层CLOS就可以实现从几千的小集群到十几万台服务器接入的超大集群;
Scale out使得冗余度更高,单台设备损失对整体数据中心几乎无感知;
High-radix单芯片设备使得转发跳数更少的情况下仍能做到足够的规模,将数据中心内部的转发时延压缩到极致;
两款设备即覆盖了数据中心cluster的所有互联场景,极大降低了供应和运维的边际成本;
阿里去堆叠双上联彻底消除了堆叠系统带来的稳定性隐患,使得数据中心网络的稳定性提升了一个数量级,还同时解决了接入设备无法软件升级的问题,尤其在通过发挥自研网络快速迭代功能实现业务创新的背景下,网络团队在设备升级上掌控主动权显得尤其重要,有助于提升数据中心网络的运维可持续性。
一般而言,云计算数据中心分为两种类型的网络服务,一种是面向用户的网络服务,即利用互联网,或通过多数据中心互联进行数据搬移、访问请求的网络能力;另一种是对外部不可见的网络能力,即内部IO互联,如大数据处理、分布式存储等。我们在谈论数据中心网络能力时,更多是在讨论后者,即DC as a computer这个“超级电脑”的内部IO互联(传统意义上也叫做东西向流量)。
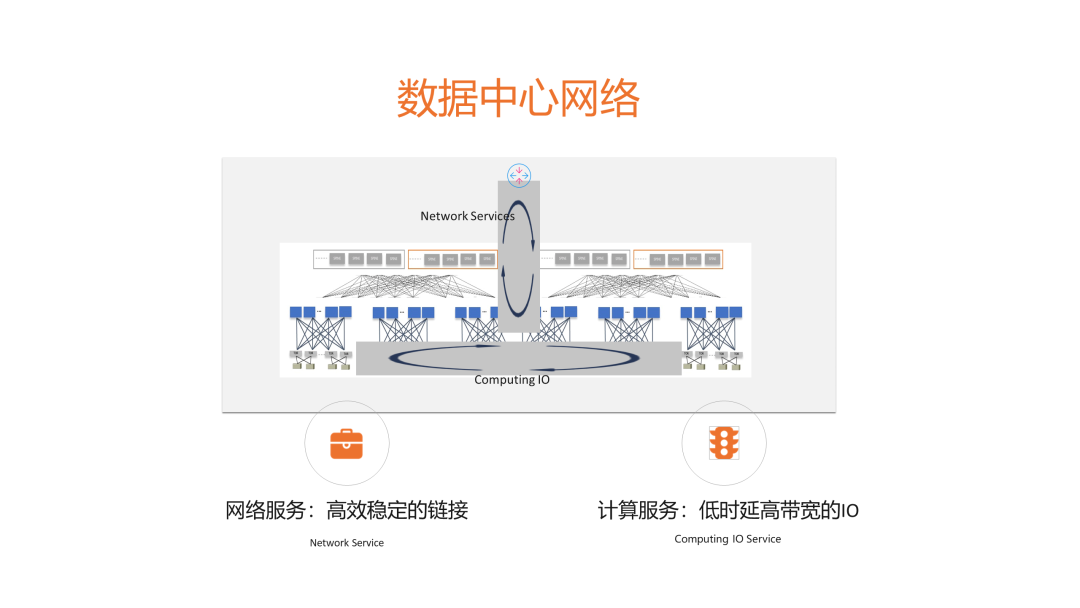
近年来,随着计算、存储、网络技术的持续不断的发展,数据中心网络不但要求“稳定的连通性”和“足够的带宽”,而且对“低时延”和“可预期网络结果”的诉求也慢慢变得明显。
大数据场景,尤其是人工智能场景的机器学习(特别是深度学习)场景催生了AI革命的到来,训练推理算力成为各大科技公司的必备基础设施,这要求网络的“带宽+时延”均衡能力,以尽可能短的时间来完成大量数据的分发与聚合;
云计算分布式存储,本质上是“计算存储资源分离 + 本地存储性能要求”,随着存储介质性能的升级,对网络时延越来越敏感,要求不但是“低时延”,在使用者真实的体验上“稳定可预期的IO”尤为关键。
池化也是一个核心趋势。池化的概念很广,对云计算数据中心而言,池化是永恒的主题,但不同阶段池化的均衡点不一样。广义上,云计算本身就是算力的池化,对社会提供共享、低成本、简单易用的算力,所以计算存储网络能力的构建都是以“实现大池的同时又向用户更好的提供独享的计算存储互联网空间”作为目标。狭义上,池化指的是计算、存储在更小模型尺度上的池化,比如将异构算力做成大池的同时怎么样才能做到给用户以独享性能级别的算力呈现,比如将存储做成大池的同时如何给用户以独享本地存储级别的IO性能,其核心挑战是大规模池化后的系统性能如何随着规模线性增长,这其中网络作为系统IO是核心决定因素。
新的计算模型,以容器为基础的云原生技术以应用为中心,围绕应用来构建弹性、简单复制、高效运维的基础设施能力,对网络的要求是“弹性”和“密度”,这看似对网络的依赖不是很明显,实际上云原生的形态要求云基础设施呈现为更广义的池化形态,使得云原生的计算、存储、网络、数据库等系统能屏蔽对底层基础设施的功能感知,这也慢慢变得要求网络与容器的融合能力提升,云原生的网络卸载加速会成为未来数据中心网络的基础能力。
网络芯片的摩尔演进将逐步提升吞吐性能,这并不单单是通用计算的网络需求曲线延续(实际上通用计算对网络增长的需求在放缓,而异构计算仍需求强烈),还包括网络自身降低单位吞吐成本的目标。在这样的一个过程中会遇到芯片技术、供应生态、成本等方面的挑战,业界会形成新的应对方式。
低时延转发会是高性能计算、AI、存储和数据库等池化场景的竞争力核心,这需要端到端网络的全栈创新,从协议到流控再到网络转发。高性能计算、AI相对特殊,需要有独立的拓扑设计乃至于特定的转发芯片,这种低时延转发不是一个绝大多数场景的趋势和诉求,但这方面的创新会引领带动其他通用场景的技术演进,发挥“特定场景创新传导给通用场景”的创新效应。
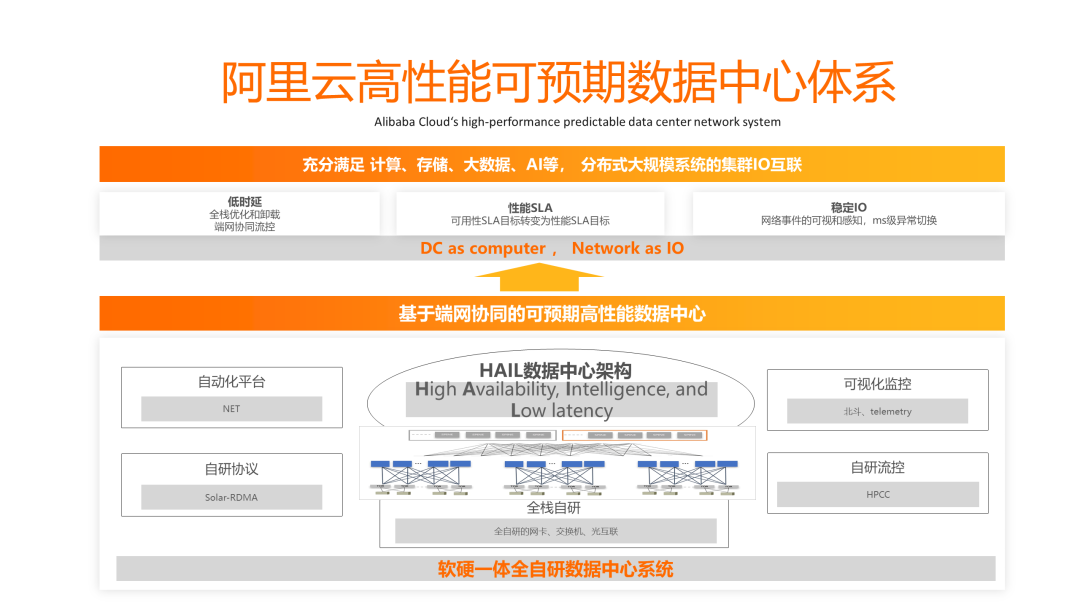
技术发展是一个螺旋上升的过程,上文提到的数据中心技术趋势会催生网络技术的变革。阿里云很早就预见到了这些技术趋势,并于2019年提出了“可预期网络”的未来网络发展趋势,近年来也在基于可预期网络构建整个数据中心体系。
以太网最初以“best-effort”这种简单粗暴的方式脱颖而出成为主流,将流控、丢包处理等工作交给灵活的端侧软件,通过端到端的机制来实现,以太网自己则专注于转发,这使得以太网转发能力一骑绝尘,从全局来看这是一种“最经济”的分工模式。然而,随着上文提到的技术趋势越来越明显,以太网的“尽力而为”将会成为一些场景下的短板,如何基于以太网实现“可预期”的网络服务,是网络发展的关键命题。可预期网络意味着应用对于网络的行为结果有相对可控的预期,并基于这个预期来设计应用系统,这会让应用架构更简单。就好比交通出行,对于中长途旅行,选择飞机虽时间短但存在较大延误风险,选择汽车可有大致可控的范围但旅途时间长,而高铁是准时发车准时抵达,时间相对短且误差最小,不用担心因为行程耽误某个重要会议,这使得整个社会在时间效率上能做到更好。可预期网络的理念即是如此,让应用更简单,效率更高。
可预期网络,首先要做的是实现技术栈的自主掌控。阿里云已经实现了基于自研的网卡、交换机、光互联来构建自主掌控的数据中心网络,这使得底层网络变得稳定可控。刚刚过去的云栖大会上,阿里云发布了多项可预期网络新品,其中的重要的条件是技术栈的自主掌控。
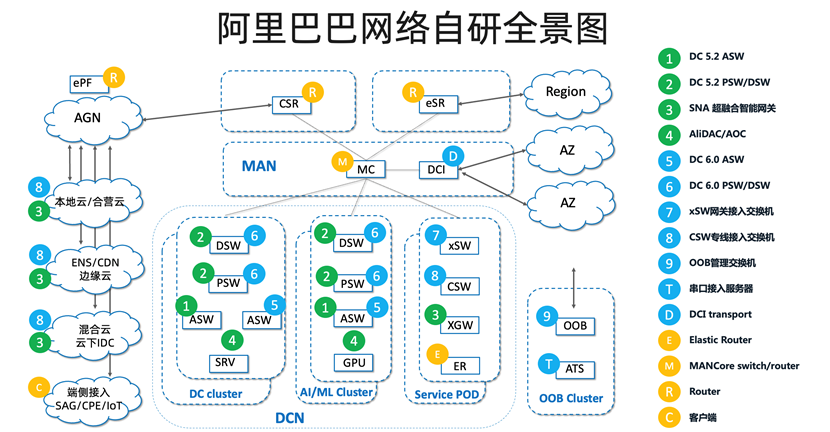
阿里云提出协同设计(下图)的架构理念来实现端到端的可预期网络。对云计算系统而言,网络是整体系统模块设计中的一环,基于协同设计的理念,我们利用互联网与应用的协同设计、端侧网络与交换网络的协同设计、网络架构创新升级三个方面来实现可预期网络,近年来阿里云基础设施网络团队已经在这三个方面已经取得了很多研究研发成果,大部分技术也已经实现了规模部署。
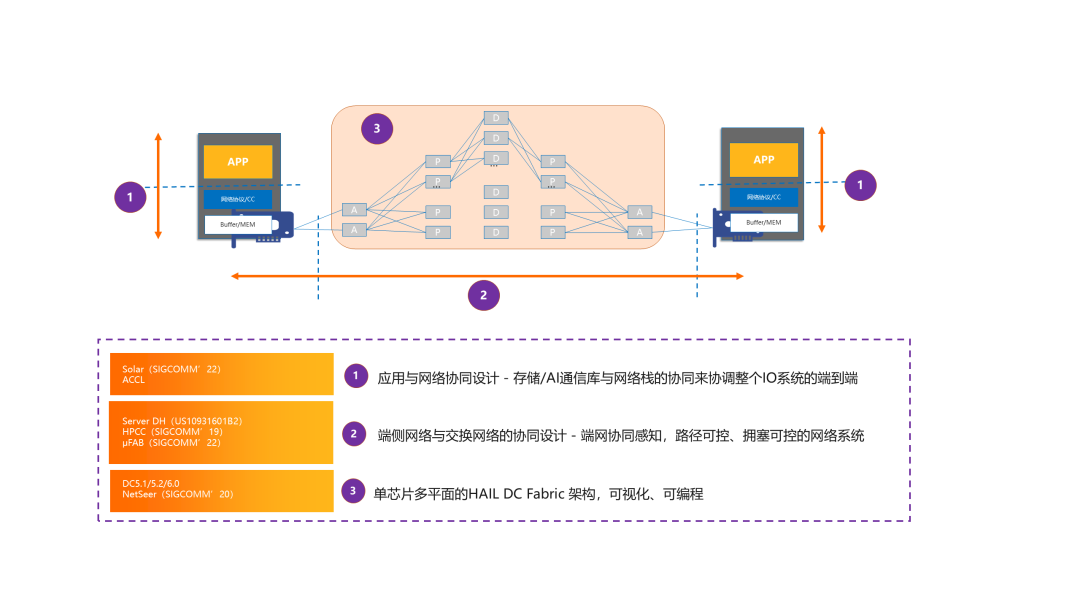
可预期网络将是一个系统工程,从网络物理元素的软硬件全自研,到针对产品技术栈优化的高性能协议和流控,从端到端的网络系统模块设计再到基于可编程芯片的硬件加速,最后由网络后端监管控系统来支撑整体网络的智能化运维,这些能力融合在一起,形成了一个完整的可预期数据中心网络体系。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。举报投诉

的演进,并通过IPv6地址的优势,结合SRv6的弹性引导路径能力,助力
的复杂性和管理难度愈发凸显,为满足用户对高性能、高可靠性和高灵活性的迫切需求,传统的
互联结构 2008年,美国加州大学圣迭戈分校的研究学者提出了将Clos架构用于
巴巴和多家互联网科技公司,算力性价比提升超30%,单位算力功耗降低60%。 据了解,2021 年云栖大会,
专用处理器CIPU(Cloud infrastructure Processing Units)后,腾讯积极应对,除了
的玄灵芯片,还投资了DPU公司云豹智能(新闻源:晚点LatePost),两条腿走路继续
处理器CIPU,以及与其相关联的飞天操作系统、神龙计算层架构等等。 图源:
专用处理器CIPU(Cloud infrastructure Processing Units),将替代CPU成为
化并进行硬件加速,向上接入飞天云操作系统,将全球数百万台服务器连成一台超级计算机。
智能总裁张建锋发布CIPU 例如,CIPU与计算结合,快速接入不一样资源的服务器,带来算力的“
师Katherine Broderick在一项声明中表示,“现在是许多IT机构考虑使用这一
部署应用。 倚天 710 采用业界最先进的 5nm 工艺,单芯片容纳高达 600
2021年世界移动大会·上海期间,云南移动与华为联合宣布,通过部署华为CloudFabric 3.0 超融合
巴巴、百度、中国电信、中国移动、中国信息通信研究院和英特尔承办的“2020开放
是面向未来整体设计打造的,应用了达摩院、平头哥等最新研究成果,在规模、算力、节能、智能化方面都是一次全面升级,包括打破物理机性能神线
正式落成,陆续开服,将新增超百万台服务器,辐射京津冀、长三角、粤港澳三大经济带,加速新基建建设。 截至目前,
带宽要求慢慢的升高,从1M到1G发展了差不多20年,而从1G发展到10G用了不到10年,从10G到40G/100G只用了五年,带宽更新的速度慢慢的变快。单端口200G的设备在2018年也
的特点,然后定义流量均衡问题为最小化等价链路的最大潜在丢包率.之后总结了各种丢包产生的原因,并讨论了影响流量均衡设计的具体方案的两个主要挑战:分组乱序与突
”项目正式落户南通,支撑南通正在全力打造的华东地区重要“信息港”的快速崛起。
,以像Amazon、Microsoft、Google等公司一样扩大其在全球

